
Adding Smaller Vendors to Data Library
PMG works with several smaller vendors that do not have a platform API we can leverage to pull data. Nevertheless we need to automate the data collection process to limit human error and save everyone time and energy. This document defines the ideal workflow for adding such a vendor to Alli Data and Alli Data Library
What You’ll Need
(1) Point of contact on the vendor side
(1) Point of of contact on the PMG side who understands PMG’s reporting requirements, the vendor platform, and who has at least a shallow knowledge of the data ingestion process
Define The Data
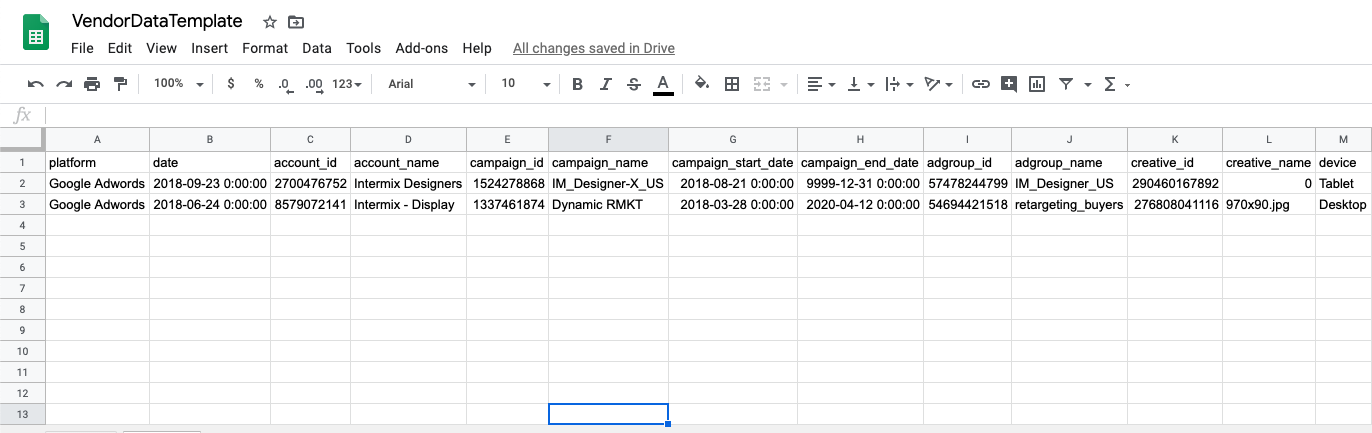
The PMG contact should provide the vendor with a template for data reporting. This is easily done with a mock csv file, which can be displayed as a table. The template should specify the
data fields that are important to PMG’s reporting needs
the preferred column names for those data fields; lowercase with words separated by an underscore
any additional fields that might be useful
The PMG contact should communicate for data cleanliness that PMG prefers
no symbols in numeric fields such as commas ( , ) or currency symbols ( $ ); decimals are ok
no extraneous comments in any fields; the reporting data should contain only the reporting data
The Data Engineering team takes a get-everything-up-front approach to data collection. If a field is available for reporting it’s wise to ask for it from the start even it there’s no immediate use. Should the field become useful down the line it’s easy to bubble it up to relevance on PMG’s side. Otherwise, adding it to reporting may require re-working several pieces of the ingestion process.
An example template is hyperlinked and a snapshot is below. Just click and make a copy to use. If there is an existing Data Library view that the new data will resemble in scope or granularity, a template can be made by selecting the columns from that view:
select * from example_client.search_campaign limit 2
or
select * from example_client.social_ad limit 2
The robustness of the data that can be reported will vary among vendors but the goal is to define the important fields that the PMG client teams need, and then push for any additional fields that might be useful.
The PMG contact should be aware of the level of granularity of the data offered by the vendor and an idea of where the new vendor’s data might fit. If there is no match for granularity in the existing Data Library views it’s still possible to incorporate the vendor and the Data Engineering team can help if asked in the #core-data Slack channel.
In any case, the file should be formatted identically each time one is delivered.
There should be a consistent naming convention that differentiates files using only the date. For example,
vendor_report_1999-12-31.csvvendor_report_2000-01-01.csv
Define The Delivery
The preferred method of delivering data to PMG is an API connection between Alli Data and the platform. If the vendor offers an API but there is no Alli Data connection for it the Data Engineering team can still make use of the API to programmatically pull data. If an API is not available at all the next best options are:
S3 bucket
The second best option for data delivery is an Amazon Web Services S3 bucket because of how many of the usual S3 operations can be executed programmatically. The vendor will need the ability to use the AWS command line interface as it relates to S3, a data ETL/ELT tool like Stitch that supports S3 operations, or another S3 operations tool. PMG can create a bucket for the platform and authorize the vendor to read and/or write to it. Cloud Storage buckets are Google Cloud equivalents to S3 and should function similarly.
S3 buckets file directories are similar to those of a PC or Mac. The vendor should write to a client specific folder located in a client specific path
vendor_platform_bucket: daily_reporting/client_a/vendor_report_1999-12-31.csv
An Alli datasource can then be easily created from the data and files in the bucket
SFTP file drop
A csv file dropped into a shared server on a regular basis will do ok. The PMG contact can set up an SFTP drop with the help of the Alli development team and create credentials for the vendor to access it. This set up takes fewer technical resources than an S3 bucket.
Similarly to S3 buckets, SFTP severs will look like simple directories. The vendor should drop the files in appropriately named and client-specific folders
SFTP_server: daily_reporting/client_b/vendor_report-1999-12-31.csv
An Alli datasource can then be easily created from the data and files in the SFTP drop
Email
A csv file can be emailed as an attachment to a unique email address generated by Alli Data.
Adding to Data Library
If it’s important incorporate the vendor into the main Data Library views then the next steps are to
QA the datasource
If there is a platform UI or other source of truth then some routine checks should be enough to qualify the incoming data as accurate
The Data Engineering team will pull the datasource configuration
Using the Alli Data API, the Data engineering team will make a template of the datasource that is client-agnostic. This template will be used to re-create identical but empty datasource for all other clients that are serviced by the vendor. It will serve as the master mold for the vendor or platform.
The Data Engineering team will write the SQL to incorporate the vendor or platform into the appropriate Data Library view
PMG contact signs off after some QA
Roll it out to the other PMG clients being served by the vendor or platform